In questo post vediamo come fare un’analisi di text mining con R. Per fare un’analisi di text mining con R utilizziamo il pacchetto tm, che è uno dei più importanti quando si parla di analisi dei testi con questo linguaggio di programmazione. Analizzare un testo con R significa ridurlo a una matrice dove quello che importa sono i termini e la rispettiva frequenza.
La prima cosa da fare è installare il pacchetto tm. tm non solo è uno dei pacchetti più importanti e completi quando si parla di text mining, ma permette di effettuare una serie di azioni di preprocessing sui testi. Se non abbiamo ancora installato il pacchetto provvediamo con l’installazione prima di richiamarlo:
install.packages(tm)
library(tm)
[/code]Ora che abbiamo il pacchetto pronto, ci procuriamo un testo da analizzare! In questo post analizziamo un testo semplice, in un altro ci occuperemo di importare un file csv che contenga magari un testo o un label e vediamo come trattarlo.
Possiamo caricare un documento o un corpus da una nostra cartella oppure direttamente da un file esterno. Io ho utilizzato il
libro Dracula presente sul sito del progetto Gutenberg.
Per prima cosa salviamo la url del nostro libro come oggetto su R. Stiamo leggendo il file direttamente dal server che contiene il nostro libro. Nulla ci vieta di scaricare il file sul nostro computer e di caricarlo su R dalla nostra cartella di lavoro oppure da un’altra cartella.
url <- "http://www.gutenberg.org/cache/epub/345/pg345.txt"[/code]
Una volta fatto questo, utilizziamo la funzione readLines() per importare il contenuto del file sulla nostra sessione di R e visualizziamo le prime righe del documento:
drac1 <- readLines(url, encoding = "UTF-8")
drac1[1:5] [1] "The Project Gutenberg EBook of Dracula, by Bram Stoker"[2] ""[3] "This eBook is for the use of anyone anywhere at no cost and with"[4] "almost no restrictions whatsoever. You may copy it, give it away or"[5] "re-use it under the terms of the Project Gutenberg License included"
[/code]Come si può vedere dal codice qua sopra, il testo è stato importato considerando ogni riga del documento come un documento a se stante. In questo caso, visto che abbiamo un singolo documento, incolliamo tutto in un unico oggetto tramite la funzione paste(), e visualizziamo l’inizio del documento:
drac2 <- paste(drac1, collapse = "")
head(drac2)
"The Project Gutenberg EBook of Dracula, by Bram StokerThis eBook is for the use of anyone anywhere at no cost and withalmost no restrictions whatsoever. You may copy it, give it away orre-use it under the terms of the Project Gutenberg License includedwith this eBook or online at www.gutenberg.org/licenseTitle: DraculaAuthor: Bram StokerRelease … "
[/code]Perfetto, ora il nostro documento si trova in un unico oggetto, che è drac2. A questo punto utilizziamo per la prima volta il pacchetto tm per creare un Corpus. Il Corpus è una struttura propria di questo pacchetto. Contestualmente vettorializziamo il nostro documento.
drac3 <- VCorpus(VectorSource(drac2))
inspect(drac3)
<<VCorpus>>
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 1
Metadata: 7
Content: chars: 851167 [/code]
Adesso procediamo con la fase di preprocessing di un testo. Il preprocessing di un testo è la sua pulizia da termini molto utilizzati, congiunzioni, avverbi e in generale le cosiddette parole “vuote”, ma anche la rimozione degli spazi aggiuntivi, e così via. Le fasi del preprocessing di un testo sono, in breve:
- tokenizzazione, ossia divisione in parole del testo stesso
- rimozione delle stopwords o parole vuote, come congiunzioni, avverbi e articoli
- stemming e rooting per ridurre le parole alle loro radici
- la normalizzazione, che include la rimozione ad esempio di errori di battitura, e la conversione delle parole in minuscolo
- l’identificazione dei limiti di frasi o preposizioni
drac4 <- tm_map(drac3, removeNumbers)
drac4 <- tm_map(drac4, removePunctuation)
drac4 <- tm_map(drac4, removeWords, stopwords("en"))
drac4 <- tm_map(drac4, stripWhitespace)
A questo punto andiamo a creare una matrice documenti x termini, o dtm. Il nostro scopo, nel fare un’analisi di text mining con R di questo tipo, è ridurre il testo a un elenco delle parole che lo compongono, utilizzando il cosiddetto modello della borsa di parole.
# creiamo quindi la DTM
dtm <- DocumentTermMatrix(drac4)
[/code]Ora visualizziamo i termini che si presentano con maggiore frequenza nel documento:
findMostFreqTerms(dtm, 10)
one the will said must may shall see know now
439 424 405 401 389 364 353 350 337 334
Proseguiamo trasformando la DTM in una matrice semplice:
mat <- as.matrix(t(dtm))
[/code]Calcoliamo i totali di riga e rimettiamo i termini in ordine, infine creiamo un grafico delle parole più utilizzate nel testo
tot_r <- rowSums(mat)
tot_r_ord <- sort(tot_r, decreasing = TRUE)
head(tot_r_ord, 10)
barplot(tot_r_ord[1:10], names.arg = names(tot_r_ord[1:10]), col = heat.colors(10))
[/code]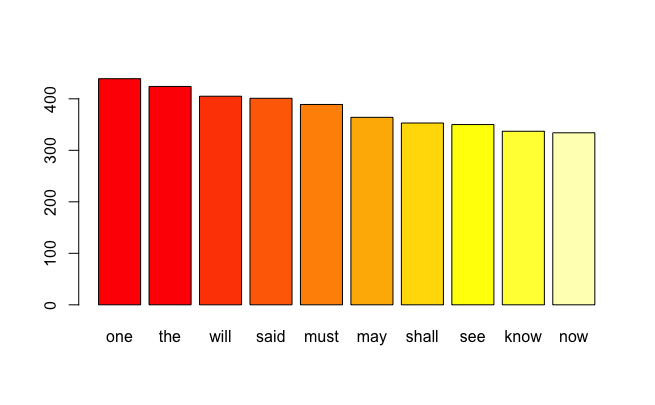
Questo è un primissimo risultato di come are un’analisi di text mining con R. In questo post hai imparato come fare un’analisi di text mining con R, importando un testo singolo, effettuando il preprocessing, trasformandolo in una matrice e poi creando il grafico delle parole più utilizzate nel testo.
Leave A Comment