Esistono molti tipi di algoritmi per il machine learning e possiamo quindi dividerli in categorie, a seconda del loro utilizzo.
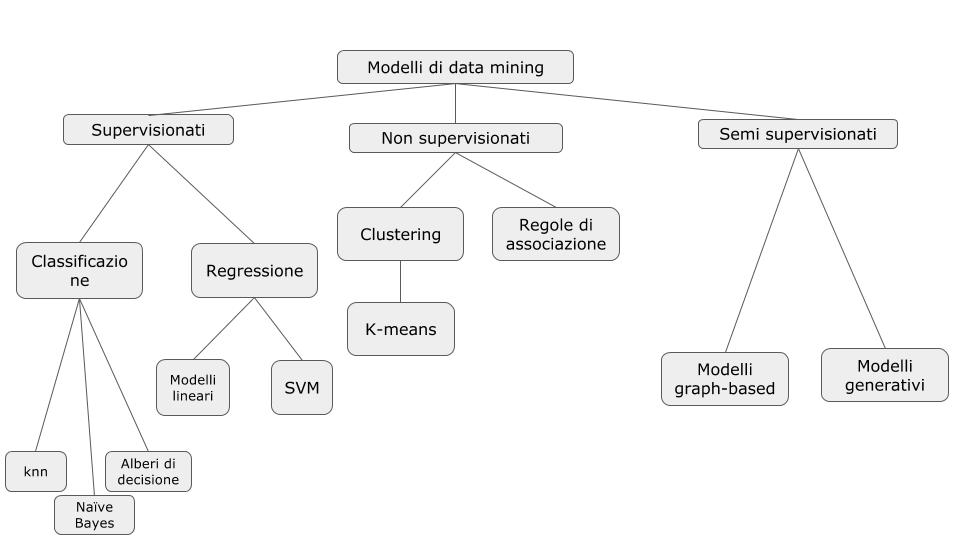
Gli algoritmi per il machine learning possono essere supervisionati, non supervisionati, semi supervisionati o attivi. Un algoritmo è supervisionato quando utilizziamo un dataset che contiene delle variabili, una delle quali è un’etichetta. In base al dataset, e tenendo come ‘ancora’ l’etichetta, l’algoritmo apprenderà (in vari modi) a classificare un dataset completamente nuovo, ma che non contiene l’etichetta, in base alle informazioni del primo dataset già classificato. Tramite gli algoritmi di classificazione, possiamo ad esempio classificare le probabilità che:
- un’email sia classificata come spam o non spam
- una squadra vincerà o perderà la prossima partita
- risultati di laboratorio
- punteggi di test
La variabile etichetta ci dice per ognuno dei casi del dataset, che esso è da intendersi in un dato modo (spam/non spam, vince/perde), mentre tutte le altre variabili sono utilizzate per costruire una logica di classificazione. Questa logica di classificazione (o classifier) verrà quindi utilizzata per classificare nuovi dataset non etichettati. A seconda del tipo di output, la classificazione sarà binaria, se include solo due classi (spam/non spam), oppure multiclasse se è possibile avere più di due output. Alcuni algoritmi di classificazione possono anche essere utilizzati per classificare altri tipi di dati, come testi o immagini, in base al loro contenuto.
Quando si parla di algoritmi per il machine learning dove l’etichetta è di tipo testuale si parla di classificazione.
Quando l’etichetta è di tipo numerico abbiamo invece delle tecniche basate sulla regressione, che è sempre una tecnica di tipo supervisionato. Ad esempio in un dataset abbiamo tutti i dati relativi alle case in una determinata zona, e in base a questo possiamo predire i prezzi. L’output della regressione è di tipo quantitativo.
Le tecniche di apprendimento non supervisionato, invece, si basano fondamentalmente sul clustering o sulle regole di associazione. Nel clustering partiamo da un dataset, stavolta non etichettato, nel quale, a partire dalle caratteristiche di un gruppo di item, gli item vengono raggruppati in un certo numero di cluster, secondo varie logiche come la similarità o la distanza.
Si possono distinguere gli algoritmi per il machine learning anche sulla base delle logiche sottostanti: ad esempio gli alberi di decisione sono modelli logici, il Naïve Bayes è di tipo probabilistico, mentre la regressione è un modello geometrico.
Per cominciare a utilizzare gli algoritmi per il machine learning, è necessario inquadrare il nostro progetto nella categoria corretta: classificazione, clustering, previsioni numeriche, o riconoscimento dei pattern.
Ad esempio, se ci troviamo di fronte a un dataset di clienti in cui una colonna ci dice se il cliente è fedele o ha abbandonato l’azienda, saremo di fronte a un problema di classificazione che ci permetterà di costruire uno o più modelli da applicare a clienti a rischio, tramite metodi come il Support Vector Machine, gli alberi di decisione o i metodi bayesiani; per scoprire se un’email è spam o meno, analizzeremo vari testi etichettati come spam o non spam e utilizzeremo le frequenze dei termini normalizzate; per predire una quantità utilizzeremo metodi di regressione; per organizzare in gruppi dei dataset non etichettati, varie tipologie di clustering come il clustering gerarchico o il kmeans, e via dicendo. La scelta di un algoritmo per il machine learning dipende fortemente dal tipo di dati che stiamo analizzando e da dove vogliamo che questi dati ci portino.
Qui sotto uno specchietto riassuntivo dei vari algoritmi per il machine learning:
ho istallato questo pacchetto ma mi da questo errore:
Errore: package ‘copula’ required by ‘CoClust’ could not be found
mi potete aiutare?